Back to Blog 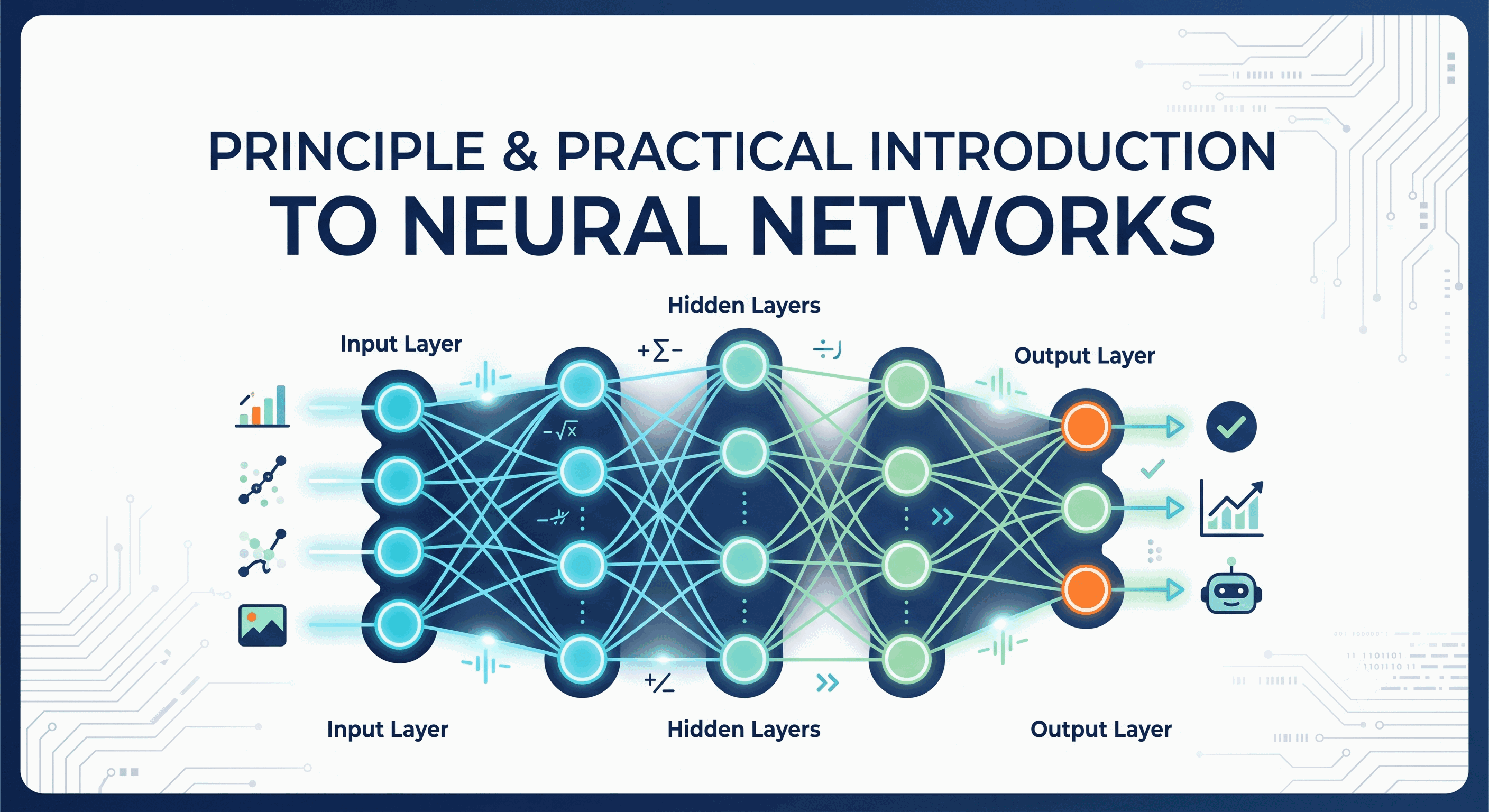

Neural networks keep evolving to become more complex structures. It is hard to understand complex neural networks without knowing the core principles of neural networks. Following this knowledge gap, you are going to study a basic, comprehensive overview of how a plain vanilla neural network works. Let's call it a
Multilayer Perceptron.Understanding Neurons
You must have heard about the term
neuron and how it is a core part of the brain and nervous system.A neural network is a mathematical model design, inspired by how the brain works. Hence, certain terms used to describe components of the neural network might be inspired by functional parts and components of the brain. In a basic neural network using a Sigmoid activation, the value of a neuron ranges from
0 to 1. This number range in the neural network is called the activation. In summary, neurons hold these numbers in neural networks.Neural networks operate in
layers which are interconnected. Layers in between the first and last layers are called the hidden layers.Activations in each layer bring about the activations in the next layer. Hence, some groups of neurons firing cause certain groups of neurons in the next layer to fire. These neural patterns formed are similar to human experience. The human brain builds recognition habits or behaviors by experience. Neural networks utilize these principles as well.
When information is passed through a neural network, certain neurons activated in a layer lead to the activation of specific neurons in the next layer, ultimately leading to the output of the last neuron layer. In a classification network, the
brightest neuron (the neuron with the highest value in the output layer) is the network's choice. This is how patterns and complex predictions are carried out in AI models based on inputs.The activations at the end of a neural network for a neuron determine how a specific input correlates with a corresponding answer. The neuron activation representing the highest digit represents the specific output that should be picked.
Finally, a neuron is essentially a mathematical function that takes in all the outputs from the previous layers and spits out an output number (often between
0 and 1, depending on the activation function).Why Layers?
Layers are essential parts of a neural network. Think of a layer as a gate of verification for an input to determine the correct output.
For instance, assuming you are told to interview a specific candidate to see if he or she is an expert in a domain. How do you know the candidate is the best for the job?
This is determined by asking more questions, background checks, reviewing experiences, projects, and more. Each of these checks acts as a layer of verification that ensures you hire the correct candidate. Although it doesn't necessarily guarantee you hire the best candidate, it reduces the possibility of hiring an incompetent candidate and increases the possibility of hiring the best talent.
From your understanding of the hiring process above, this is exactly the same principle upon which layers work. The more layers in a neural network, the higher the possibility of providing the correct output for an input. Although adding more layers is computationally expensive, it reduces the possibility of wrong predictions.
The Training Process
Now, let's dive into how neural networks learn. Neural networks learn based on the mathematical framework used. The time of training (learning process) depends on the algorithmic efficiency of the mathematical equation.
Note: For a neural network to be trained well, it needs to be initialized. Formerly, small samples of data were used in training neural networks; however, today, it is common to use massive datasets. Training iteratively updates the final weight and bias values according to the model's errors on the training data.
Let's demystify the equation behind the learning process:
- Activation -
- Weights -
- Bias -
- Sigmoid -
The activation in each layer is based on the sigmoid function of a weighted sum; all the activations from the previous layer are multiplied by their weights, combined, and then added to a bias.
The sum of all of the inputs from the previous layer is passed through a sigmoid equation, transforming the equation to be:
Shortened Equation
The above training equation doesn't guarantee accuracy on its own. Remember, models need to learn; hence a neural network needs a correction mechanism to become more accurate in recognizing inputs. In a neural network, this is driven by the
Cost Function.The output of the cost function is small when the network classifies the final output correctly, but it increases significantly when the network classifies the output wrongly.
The aim of the Cost Function isn't only to tell how wrong the system is, but to determine how to make the system more accurate.
To minimize the value of the cost function, the neural network finds the values of model parameters (weights and biases) that minimize this loss (cost) function. This is typically done through an optimization algorithm known as
Gradient Descent. In this process, a local minima is usually found, however, it is notoriously hard to guarantee finding the global minima.The algorithm for computing the gradient efficiently—which is indirectly how this neural network learns—is called
Backpropagation.NOTE: A common Cost Function (Mean Squared Error) is calculated by taking the intended output, subtracting the model's prediction, and finding the square of the subtracted value.
You cannot directly change activations; you only have influence over the weights and biases during training.
To understand how neurons are conceptually connected, we can look to a biological principle called Hebbian Theory.
Hebbian Theory: Neurons that fire together, wire together.
Following the above theory, while we typically don't physically "disconnect" neural links in a standard dense neural network (though techniques like pruning exist), we can strengthen the connection of correct neural pathways through backpropagation using gradient descent (e.g.,
Stochastic Gradient Descent) to lay more emphasis on the correct neural path for a particular input. While doing this individually for each input is computationally costly, it is usually carried out in groups called "batches." The average of the desired weight changes is then applied to the neural network overall using backpropagation. This collective process is more efficient, trading off slight per-step accuracy for immense computational savings.Function for average of all training examples
Backpropagation uses the
Chain Rule from calculus to find the derivatives of individual components in each layer.Note: To ensure high accuracy, large quantities of quality training data are needed by neural networks. A reason why there are AI annotation jobs and high demand for data is because the quality and quantity of data strictly dictate the strength and accuracy of neural networks. However, this doesn't eliminate the need for advanced mathematical equations and optimization functions to increase model efficiency.
Conclusion
If you have made it this far, congratulations. From the overview above, you have learned the basic principles of how neural networks work and how each activation in each layer is mathematically linked to the previous activations and their weights. You have also learned that more quality data makes a neural network more powerful, along with the principles and purposes of cost functions, activation functions, weights, sigmoid, and bias. Now that you have learned these basics, you can use this knowledge to understand how different types of complex neural networks and LLMs work.
Zealynx Security Brief
Monthly vulnerability spotlights, exploit breakdowns, and security insights. Join security-conscious devs.
No spam. Unsubscribe anytime.
Ready to Secure Your AI Systems?
At Zealynx, we specialize in comprehensive AI security assessments that go beyond traditional smart contract audits. Our team applies the cognitive security framework and mathematical analysis you've learned throughout this series to identify vulnerabilities in:
- LLM Applications - Prompt injection, context manipulation, data extraction
- AI Agent Systems - Multi-modal attacks, tool misuse, privilege escalation
- ML Pipeline Security - Training data poisoning, model extraction, adversarial inputs
- AI Infrastructure - API security, access controls, deployment vulnerabilities
What makes our AI audits different:
- Deep understanding of cognitive attack vectors and mathematical vulnerabilities covered in this series
- Analysis of optimization-based poisoning, information leakage, and graph manipulation attacks
- Practical remediation strategies tailored to your AI architecture
- Ongoing security monitoring and threat intelligence
FAQ
1. What is a Multi Layer Perceptron?
A Multi Layer Perceptron (MLP) is one of the foundational architectures of feedforward artificial neural networks. It consists of at least three layers of nodes: an input layer, a hidden layer, and an output layer. Except for the input nodes, each node is a neuron that uses a nonlinear activation function.
2. How is Information Processed in Each Layer of a Neural Network?
Information is processed sequentially. Inputs to a layer are multiplied by their respective weights, summed together, and a bias is added. This weighted sum is then passed through an activation function (like Sigmoid or ReLU) to determine the final output (activation) of that neuron, which is then passed as an input to the next layer.
3. What are the functions of Hidden Layers in Neural Networks?
Hidden layers are responsible for extracting patterns and features from the input data. While the input layer receives raw data and the output layer makes the final prediction, the hidden layers perform the complex mathematical transformations necessary to understand the non-linear relationships in the data.
4. Why is a Biological Theory Concept like Hebbian Theory used in Neural Networks?
Hebbian theory ("neurons that fire together, wire together") originally described biological synaptic plasticity. In artificial neural networks, this concept loosely inspired the way weights are updated during training: when an input consistently contributes to a correct output, the mathematical "connection" (weight) between those neurons is strengthened.
5. How do Neural Networks Learn?
Neural networks learn by minimizing their errors. During training, the network makes a prediction, and a Cost Function calculates how wrong that prediction is compared to the actual answer. An optimization algorithm like Gradient Descent, powered by Backpropagation, then works backwards through the network to adjust the weights and biases to reduce this error.
6. What happens if Low Quality Data and Large Quantities of Data are used in Training a Neural Network?
If a neural network is trained on a massive amount of low-quality data (e.g., noisy, biased, or incorrectly labeled data), the model will learn those incorrect patterns. This phenomenon is often summarized as "Garbage In, Garbage Out." A large quantity of data cannot overcome the fundamental flaw of poor data quality.
7. How do we Train Neural Networks Efficiently?
Efficient training involves several techniques, including using powerful hardware (like GPUs/TPUs), optimizing data pipelines through batching (e.g., Stochastic Gradient Descent), utilizing better activation functions (like ReLU instead of Sigmoid to prevent vanishing gradients), and applying techniques like normalization and dropout to speed up convergence and prevent overfitting.
Glossary
- Multi Layer Perceptron - A feedforward neural network with one or more hidden layers.
- Layers - Groups of neurons that transform input data as it moves through the network.
- Hidden Layers - Intermediate layers between the input and output layers.
- Neurons - Units that compute weighted sums and apply activation functions.
- Activation - The output value of a neuron after its activation function is applied.
- Weights - Trainable parameters that scale the input signals for each neuron.
- Bias - A trainable parameter added to a neuron's weighted input before activation.
- Sigmoid - An activation function that maps values to a range between 0 and 1.
- Cost Function - A function that measures the error between predicted and actual outputs.
- Gradient Descent - An optimization algorithm that adjusts weights to minimize the cost function.
- Back Propagation - The process of computing gradients for each weight using the chain rule.
- Local minima - A point where the cost function is lower than nearby values but not necessarily the lowest overall.
- Global Minima - The point where the cost function attains its lowest possible value across the parameter space.
- Chain Rule Expression - The mathematical rule used to compute derivatives of composite functions during backpropagation.
Get funded for your audit
Core grants cover up to $32k. Growth and Builder tiers available. Rolling applications.
No spam. Unsubscribe anytime.