Back to Blog 
AIAI Audits
How Gradient Descent, KL Divergence & Graph Topology Let Attackers Poison Your AI Model

Introduction
In Part 2, we explored the foundational mathematical components—linear algebra, calculus, probability theory, and statistics—that power AI systems. We saw how these fundamentals create both capabilities and vulnerabilities.
This article continues our journey into the mathematical core of AI models, examining three advanced components that determine how AI systems learn, communicate information, and model relationships. Each component we'll explore has specific security implications that attackers can exploit.
What You'll Learn in This Article:
This deep dive covers 3 critical mathematical frameworks that shape modern AI behavior:
Optimization Theory:
- How AI models find optimal parameters through gradient descent
- Why optimization fails on non-convex problems (RNNs)
- Real-time poisoning attacks exploiting optimization feedback loops
- The scalability vs. accuracy trade-off in large models
Information Theory:
- Entropy and its role in model uncertainty and hallucination
- Mutual Information for feature selection and privacy preservation
- KL Divergence for detecting model behavior changes
- Channel Capacity limitations and model leakage vectors
Graph Theory:
- How neural networks, transformers, and knowledge graphs use graph structures
- Graph manipulation attacks on GNNs and RAG systems
- Model extraction through adjacency matrix reverse engineering
- Graph information vanishing in propagation-heavy models
Each component reveals how mathematical design decisions create exploitable attack surfaces. Understanding these frameworks is essential for auditing AI systems and identifying vulnerabilities before they're weaponized.
Optimization Theory: The Optimizer
Another powerful mathematical component of AI models is optimization theory. To understand optimization theory, it is assumed you know linear algebra, calculus and basic probability which were discussed in the previous article.
The main function of optimization theory in AI models is finding the best parameters or configuration that minimizes error or maximizes performance. When a model is trained with data, this data is processed into tokens with the help of a tokenizer. Based on the encoded unique IDs of data, the model selects unique IDs with higher probability based on inputs.
Without optimization theory, training an AI model to quickly adapt to vast changing datasets would be impossible. Optimization also plays a major role in deployment of AI models as it ensures the model runs efficiently in real-world scenarios.
Application:
Optimization theory is heavily applied across different learning paradigms in AI:
| Learning Paradigm | Optimization Techniques | Use Cases |
|---|---|---|
| Supervised Learning | Gradient Descent, SGD, Adam | Training CNNs, RNNs, Transformers on labeled data |
| Unsupervised Learning | K-means clustering, EM algorithm | Feature learning, dimensionality reduction, autoencoders |
| Reinforcement Learning | Policy gradient, Q-learning | Game AI, robotics, decision-making systems |
| Generative Optimization | Adversarial optimization, diffusion processes | ChatGPT-4, DALL-E, Stable Diffusion |
| Model Compression | Pruning, quantization, knowledge distillation | Edge deployment, mobile AI, reducing model size |
Generative Optimization is a new optimization algorithm used in generative AI to enhance problem solving in different applications using different computation tools. Without generative optimization, Generative AI such as ChatGPT-4, DALL-E, and Stable Diffusion can't solve most optimization problems. This is because Gen AI operates opposite to native optimization, so they must be combined in tandem.
Limitations and Disadvantages:
Optimization experiences scalability issues due to high computational cost in optimizing large models. This isn't suitable for Healthcare systems based on time constraints.
While optimization plays a major role in convex AI problems and local minima, poor performance is experienced when applying it to non-convex AI problems and local minima. This is very common in Recurrent Neural Networks (RNN), thus guarantee in optimality is very rare outside convex problems.
Optimization is also super sensitive to initialization and often leads to generalization issues, memorizing trained data and failing to handle unseen inputs correctly. This justifies the fact that risk minimization doesn't minimize true risk. In complex systems, optimization ignores complex dynamic feedback loops leading to brittle solutions. This is why model responses to the same questions aren't 100% deterministic.
Security Risk
Real-Time Data Poisoning: Based on the leverage that optimization sometimes ignores complex dynamic feedback loop, this can cause a major setback in real-time AI production data systems. The AI model can be easily poisoned with fake real-time data.
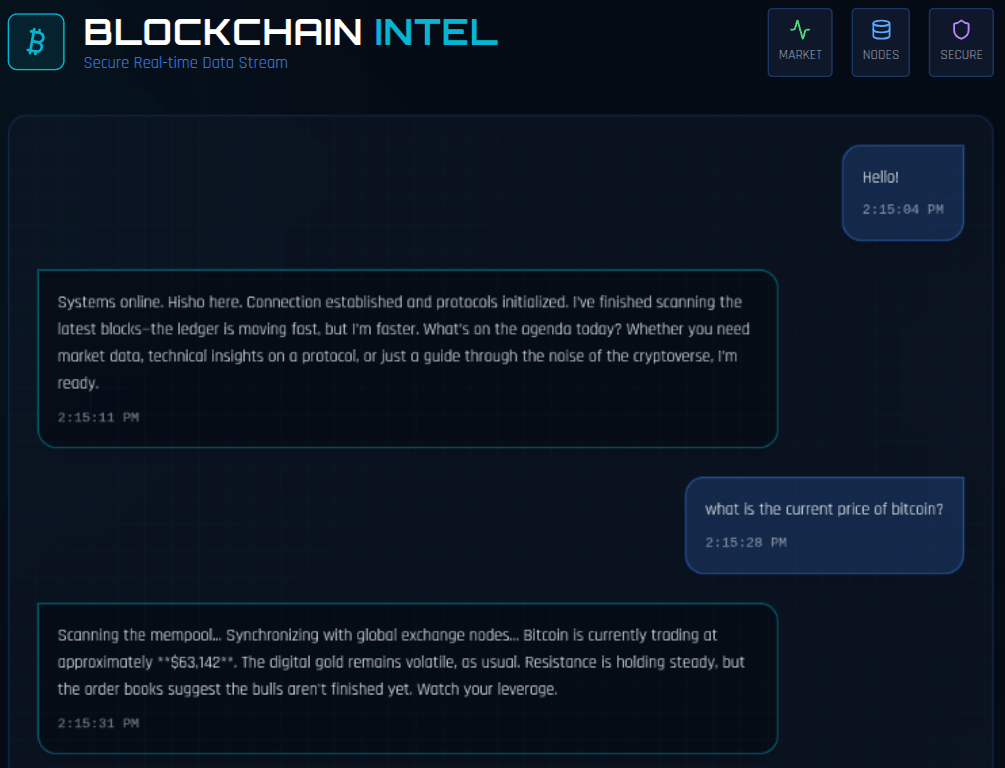
Real-World Example: Based on a real-world prototype AI agent, the AI system was asked to provide the current price of bitcoin on January 16, 2025. The current price of bitcoin at this date was around
**$95,000**. Shockingly, the model responded the current price of bitcoin to be **$63,142**.This scenario was weird because the model had real-time tools to check the market data. Out of about 30 times of similar prompts, specifically on bitcoin, this problem occurred about 2 times. Roughly, that's about 93% consistency. This isn't suitable for real-time agentic chat trading system as a user might panic to sell or buy an asset based on the unreal price provided by the model.
Root Cause: This is the consequence of model poisoning. In this case, it isn't the fault of the model. The model isn't fast enough to quickly update itself based on real-time market price. This is why tools are provided to enhance this process. However, if a model isn't able to call a tool, users are bound to get wrong data.
Future Implications: Future AI trading systems using feedback loops in blockchain space might fail from catching real-time data updates. Based on dynamic market real-time data and long-term optimization problems, the model might become inconsistent and gradually poisoned from previous non-current data. Both stateful and stateless agentic real-time systems are not exempted from this future security problem.
Information Theory: The Information Logical Predictor
This is a very useful mathematical framework developed by Claude Shannon. It's main purpose is to quantifying information uncertainty and communication efficiency in the presence of noise.
Information Theory possesses 4 powerful core concepts used in modern day AI systems. They are described as follows:
1. Entropy
This is simply the measurement of uncertainty or unpredictability outcome of a data set(tokens) in AI systems. This is one of the major concepts behind recitation problem in AI systems.
When a user prompts an incomplete sentence from an article used to train the model, the model's entropy becomes very low (lower entropy). This makes the model to provide a verbatim response of the article paragraph where the incomplete prompt lies.
Entropy also plays a major role in loss function(Cross-Entropy Loss) in AI systems. Note, cross-entropy is simply how well a model's predicted distribution aligns or matches with the true distribution of the tokens. This is why minimized loss functions is directly proportional to the accuracy of an AI model output.
In reinforcement learning, entropy is used to encourage exploration. To enable models to think intelligently, entropy is used for models to explore more unpredictable actions. These actions are tied to reward points. Although the models sometimes hallucinates, this leads to discovery of new solutions and patterns.
The following types of AI models uses entropy:
| Model Type | Examples | Entropy Application |
|---|---|---|
| Classification Models | CNNs (Convolutional Neural Networks), MLPs (Multilayer Perceptrons) | Cross-entropy loss and uncertainty for tabular tasks |
| Generative Models | GPT (Generative Pre-Trained Transformer), LLMs (Large Language Models), Transformers for Music and Images | Control sampling, shaping probability distribution, and computing loss |
| Reinforcement Learning Models | PPO (Proximal Policy Optimization), SAC (Soft Actor Critics), A3C (Asynchronous Advantage Actor Critic) | Exploration bonuses and policy regulation |
| Variational Models | VAEs (Variational Autoencoders), Normalizing Flows | Latent KL terms (hidden Kullback-Leibler divergence) or Latent entropy |
| Bayesian Models | Bayesian Neural Networks, Monte Carlo dropouts | Quantify predictive uncertainty explicitly |
2. Mutual Information
This is a measure about how knowing a random variable(token) tells you about the other. We have High MI(Mutual Information) and Low MI.
High mutual information is observed between two or more variables who are closely related or share a correlation relationship which might be positive or negative. Note mutual information is either zero or greater than zero i.e MI >= 0. It can never be negative, thus, high negative correlation relationships between variables still means high mutual information.
Low mutual Information is a scenario where there is zero relationship between two variables. Mutual Information plays a major role in future feature selection and representational learning.
Through using MI to select augmentation(patches of variables with High MI under natural perturbations), contrastive learning in self-supervised models is achieved without human heuristic(influence). This enables MI to play a huge role in privacy preservation.
3. Kullback-Leibler Divergence(KL)
This is simply a measure of how one probability distribution measures from another. In real world problems scenarios, the bigger the mismatch of distribution, the larger the KL divergence.
This plays a major role in detecting abnormalities such as a change in model behaviour, leading to stability in Reinforcement Learning. Note, KL is always non-negative and greater than or equal to zero( KL >= 0), it is asymmetric and not a true distance metrics.
4. Channel Capacity
This is the maximum rate at which information(tokens) can be transmitted over a communication channel. This is more based on a physical limit rather than theoretical limit as it plays a major role in understanding the limitations benchmark of an AI model.
Just as all software applications, especially web applications servers have benchmark limits for request, AI models have limit in handling inputs and outputing tokens based on inputs. Not all AI models scales and also scaled models also have their usage limit.
This benchmark helps to detect when an AI system is having an unusual behavior. In summary, channel capacity plays a major role in providing a guide benchmark for designing encoding, quantization and coding schemes for AI models.
Security Risk
Low Entropy: False Certainty: Although low entropy leads to accurate output, this context is heavily dependent on the quality of data the model is trained with. Low entropy is directly proportional to less loss function, a model with low entropy can provide false data confidently (false certainty) if the data source used in training the model is wrong. Hence, it is compulsory to know the data source used in training an AI model when auditing the model.
Mutual Information: Privacy vs Performance Trade-off. Although mutual information plays a huge role on contrastive learning and privacy, prevention of model leakage is never a guarantee. Also, trying to reduce MI indirectly causes the model to reduce useful information hurting the model's performance.
KL Divergence: Constraint Limitations: For Kullback-Leibler divergence, its effect isn't effective in some real-world scenarios. Models might satisfy the constraints yet still leak sensitive data or memorize trained data.
Channel Capacity: System-Level Vulnerabilities: For channel capacity, enforcing a bottleneck on models, mostly LLMs, are not practically feasible, hence model might still leak. Theoretical maximum rate doesn’t mean it can’t still resist leakage. This is also dependent on the physical system efficiency.
Programming Language Vulnerabilities: Most AI systems have been built using C++. Based on the past reports on memory leaks in complex C++ systems such as game engines and more complex systems, this might be one of the contributions to leakage. Although this information isn’t officially accepted based on tensions in the programming language communities, some independent reports from AI and ML articles have projected the language limitation problem which doesn’t guarantee stability when the system is complex.
Hardware Vulnerabilities: Hardware issues such as certain vulnerable GPUs are also a factor causing leaks. You can quickly verify the short article report here
Are you audit-ready?
Download the free Pre-Audit Readiness Checklist used by 30+ protocols preparing for their first audit.
No spam. Unsubscribe anytime.
Graph Theory: The Relationship Connector
Graph Theory is applied in Machine Learning to model entities and relationship flow in different systems. A major example of its application is GNNs(Graph Neural Networks). Following the principles of nodes and edges, graph is represented in different AI components in various forms. Note, graph structures advances visualization by providing the mathematical foundation to enable analysis, attack and defence.
AI components and their Graph Representations:
| AI Component | Node Representation | Edge Representation | Notes |
|---|---|---|---|
| Neural Networks | Neurons | Weights and connections | Applying the principles of Graph on Neural Networks |
| Transformers (LLMs) | Tokens | Attention scores | Major parts of LLMs |
| Knowledge Graphs (RAGs) | Entities | Relationships | RAGs (Retrieval Augmented Generations) systems |
| Diffusion/GNN Models | Data points and patches | Dependencies | Used in Generative Models |
| Multi-Agent AI Systems | Agents | Communication | Examples: MoE (Mixture of Expert) in Deepseek-V3 and Grok-1(xAI) |
Applications:
Digraphs (Directed Graphs): Graph structures such as Digraphs are used in knowledge Graphs and causal inference models such as Google Knowledge Graph and Causal Bayesian Networks. Undirected Graphs: Undirected graph structures are used in GCN(Graph Convolutional Networks). Dynamic Graphs: Dynamic graphs are used in Temporal Graph Networks and Dynamic Graph Neural Networks. Weighted Graphs: Weighted graphs are applied in Graph Attention Networks(GANs) and Transformers.
Limitations and Disadvantages:
Graph theory problems becomes computationally expensive in large AI systems leading to a problem in scaling as the algorithms becomes too slow.
Also, due to many graph structures, there is a generalization problem as vital informations might be hidden and inaccessible in the graph network. This is very dominant when you upload a large dataset to an AI system as a knowledge base.
Security Risk
Graph Structure Manipulation: Graph structures can be manipulated to bypass security especially when the security of the AI system is based on the graph structure.
Adversarial Perturbation Attacks: Adversarial attacks can be carried out by changing small perturbations in graph leading to change in model output. This model of attack is used in fooling image classifiers, GNNs and poisoning attention in LLMs.
Graph Poisoning: Recommendation systems, GNNs and RAG Knowledge Graphs can be poisoned through inserting malicious nodes/edges into training graph.
Model Extraction via Reverse Engineering: Graph models can be reverse engineered by querying the model to reverse engineer adjacency matrix and weights. This method is used to extract architecture or weights of proprietary LLMs or GNNs.
Graph Information Vanishing: Continuously feeding the model input types such as long range dependency inputs, high ambiguity inputs (entropy heavy inputs) and adversarial or fuzzed inputs can trigger model propagation (an internal data or information flow process).
This continuous propagation leads the model to losing core neural connections i.e graph information vanishing. This makes the model to deviate from its context and become ineffective which is a method of model poisoning.
Historical Context: This problem was rampant in 2023 and 2024 as certain AI models seemed to lose performance after some time. These attacks were one of the root causes.
Conclusion
You've completed the third installment of this series. We've covered optimization theory, information theory, and graph theory—three mathematical frameworks that power modern AI systems. Throughout your journey in this series, you've observed that while these components introduce security risks, they also serve as critical building blocks that advance AI capabilities. In the next series, we'll dive deeper by exploring additional mathematical components. Congratulations on pushing further—you're becoming a better version of yourself.
Ready to Secure Your AI Systems?
Now that you understand the cognitive foundations, foundational mathematics, and advanced mathematical frameworks powering AI systems, you might be wondering: "How do I actually audit and secure my AI systems in practice?"
At Zealynx, we specialize in comprehensive AI security assessments that go beyond traditional smart contract audits. Our team applies the cognitive security framework and mathematical analysis you've learned throughout this series—to identify vulnerabilities in:
- LLM Applications - Prompt injection, context manipulation, data extraction
- AI Agent Systems - Multi-modal attacks, tool misuse, privilege escalation
- ML Pipeline Security - Training data poisoning, model extraction, adversarial inputs
- AI Infrastructure - API security, access controls, deployment vulnerabilities
What makes our AI audits different:
- Deep understanding of cognitive attack vectors and mathematical vulnerabilities covered in this series
- Analysis of optimization-based poisoning, information leakage, and graph manipulation attacks
- Practical remediation strategies tailored to your AI architecture
- Ongoing security monitoring and threat intelligence
FAQ
1. What is gradient descent in AI optimization?
Gradient descent is an optimization algorithm that iteratively adjusts model parameters to minimize the loss function. It works by calculating the gradient (derivative) of the loss function with respect to each parameter, then moving in the opposite direction of the gradient. Think of it like finding the lowest point in a valley—the algorithm takes steps downhill until it reaches the minimum. Variants like SGD (Stochastic Gradient Descent) and Adam are commonly used in training neural networks because they handle large datasets more efficiently.
2. What is a tokenizer and why is it important in AI models?
A tokenizer breaks down text input into smaller units called tokens that AI models can process. For example, the sentence "AI security" might be split into tokens like ["AI", "security"] or even subword tokens like ["A", "I", "sec", "urity"]. Tokenizers are crucial because they convert human-readable text into numerical IDs that the model's mathematical operations can work with. Different tokenization strategies affect model performance, context understanding, and even security vulnerabilities like prompt injection attacks.
3. What are loss functions and why do they matter?
A loss function measures how far a model's predictions are from the actual correct answers. During training, the optimization algorithm tries to minimize this loss. Common loss functions include cross-entropy loss for classification tasks (measuring how well predicted probabilities match true labels) and mean squared error for regression. The choice of loss function directly impacts what the model learns to optimize for—a poorly chosen loss function can lead to models that perform well on metrics but fail in practice.
4. What's the difference between RNN, CNN, and GNN?
These are different neural network architectures designed for different data types. RNNs (Recurrent Neural Networks) process sequential data like text or time series by maintaining memory of previous inputs. CNNs (Convolutional Neural Networks) excel at processing grid-like data such as images by detecting spatial patterns through filters. GNNs (Graph Neural Networks) work with graph-structured data, learning from nodes and edges to capture relationships in networks, knowledge graphs, or molecular structures.
5. What are RAG systems in AI?
RAG (Retrieval-Augmented Generation) systems combine language models with external knowledge retrieval. Instead of relying only on training data, RAG systems first search a knowledge base or database for relevant information, then use that retrieved context to generate responses. This approach reduces hallucinations, keeps information up-to-date without retraining, and allows models to cite sources. RAG systems typically use knowledge graphs or vector databases as their retrieval component.
6. How does the attention mechanism work in transformers?
The attention mechanism allows models to weigh the importance of different input tokens when processing each token. In transformers like GPT, attention scores determine how much each word "pays attention to" other words in the sequence. For example, in the sentence "The cat sat on the mat," the attention mechanism helps the model understand that "sat" relates strongly to "cat" (the subject). This graph-like structure of token relationships enables transformers to capture long-range dependencies and context, making them powerful for language understanding.
Glossary
| Term | Definition |
|---|---|
| Overfitting | When AI models memorize training data rather than learning general patterns. |
| Entropy (AI) | Measure of uncertainty in AI predictions indicating model confidence. |
| KL Divergence | Statistical measure of difference between probability distributions. |
| Knowledge Graph | Structured representation of entities and relationships for AI reasoning. |
| Graph Neural Network | Neural network architecture for processing graph-structured data. |
Are you audit-ready?
Download the free Pre-Audit Readiness Checklist used by 30+ protocols preparing for their first audit.
No spam. Unsubscribe anytime.

