
OWASP ASI04 Explained: Agentic Supply Chain Attacks
OWASP ASI04 (Agentic Supply Chain Vulnerabilities) explained: MCP Impersonation, malicious tools, trojanised connectors. Real CVEs, attack patterns, mitigations.
ReadAI security, MCP server reviews, and red-team write-ups across smart contracts, dApps, and Web2 infrastructure.
OWASP ASI04 (Agentic Supply Chain Vulnerabilities) explained: MCP Impersonation, malicious tools, trojanised connectors. Real CVEs, attack patterns, mitigations.
Read
Complete MCP vulnerability index: 16 disclosed breaches and 14+ CVEs since April 2025 across Anthropic, Cursor, Postmark — with OWASP ASI04 patterns. Updated weekly.
Read
Build an AI auditor agent that actually works. Multiple paths modeled after the best existing tools, benchmarked against 118 real Code4rena findings.
Read
Complete guide to Web3 supply chain attacks with 5 vectors, real incidents, and actionable checklist.
Read
Learn the Act of Jailbreaking an LLM using Paradox-Inspired Techniques
Read
Discover how LLMs Threat detection rate can be reduced for Successful Injection
Read
Understand the Architecture and Security Layers of a Customer Agent Orchestration System
Read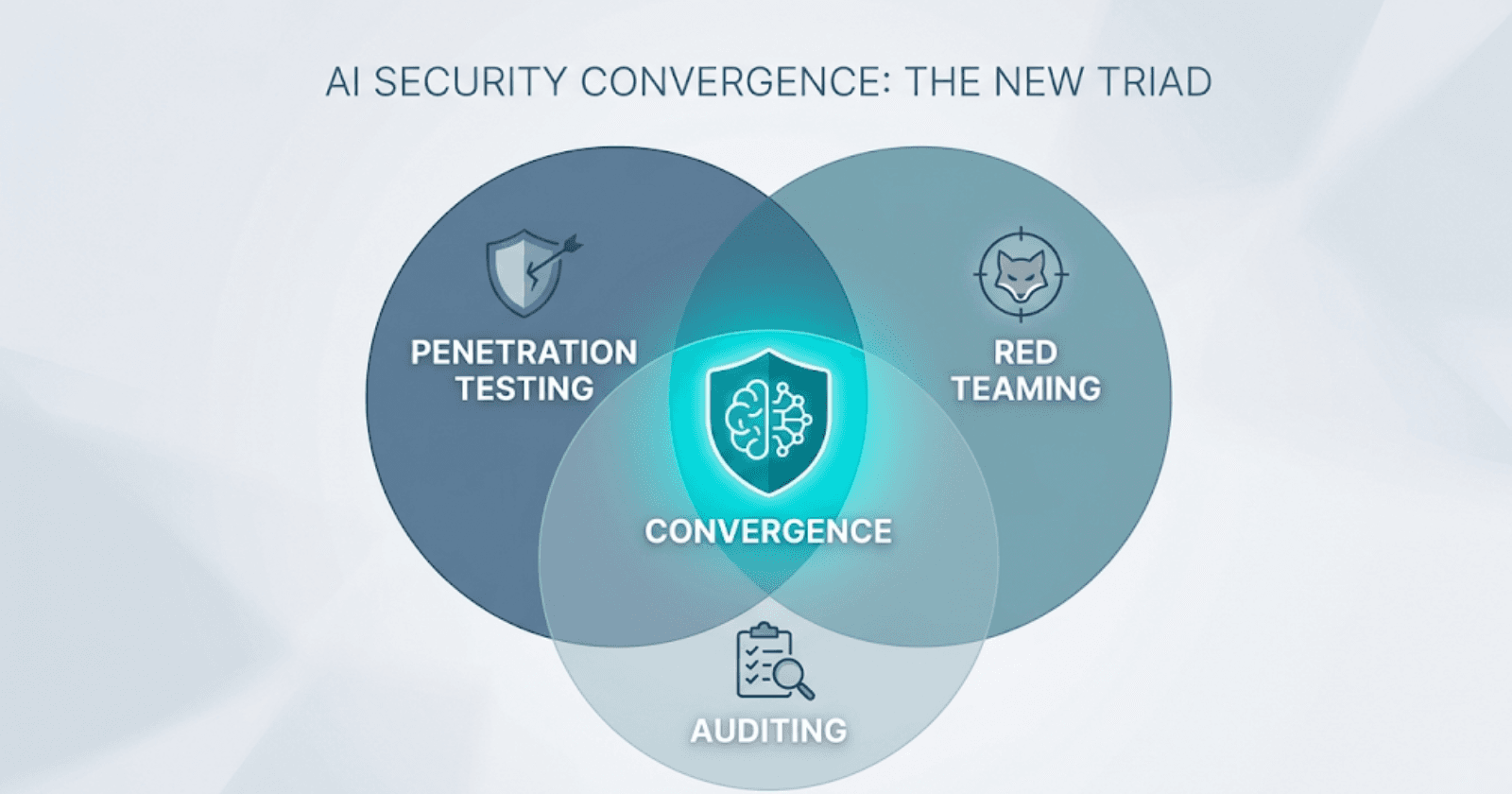
Pentesting finds bugs, red teaming tests defenses, audits prove compliance. Learn why AI security demands all three integrated into one TEVV lifecycle.
Read
Secure your MCP servers against prompt injection, credential theft, and supply chain attacks. A practical hardening guide for identity, transport, and runtime.
Read
Five systemic vectors targeting AI trading bots — adversarial ML, data poisoning, prompt injection, API exploits, supply chain compromise — with strategic mitigation.
Read
How prompt injection drains AI-controlled DeFi vaults. Freysa and AiXBT exploits analyzed, EVMbench data, and defense architecture for autonomous agents.
Read
DNS hijacks, supply chain attacks, and UI social engineering bypass smart contract security entirely. Learn how attackers exploit web apps to drain DeFi protocols and how to stop them.
Read