Back to Blog 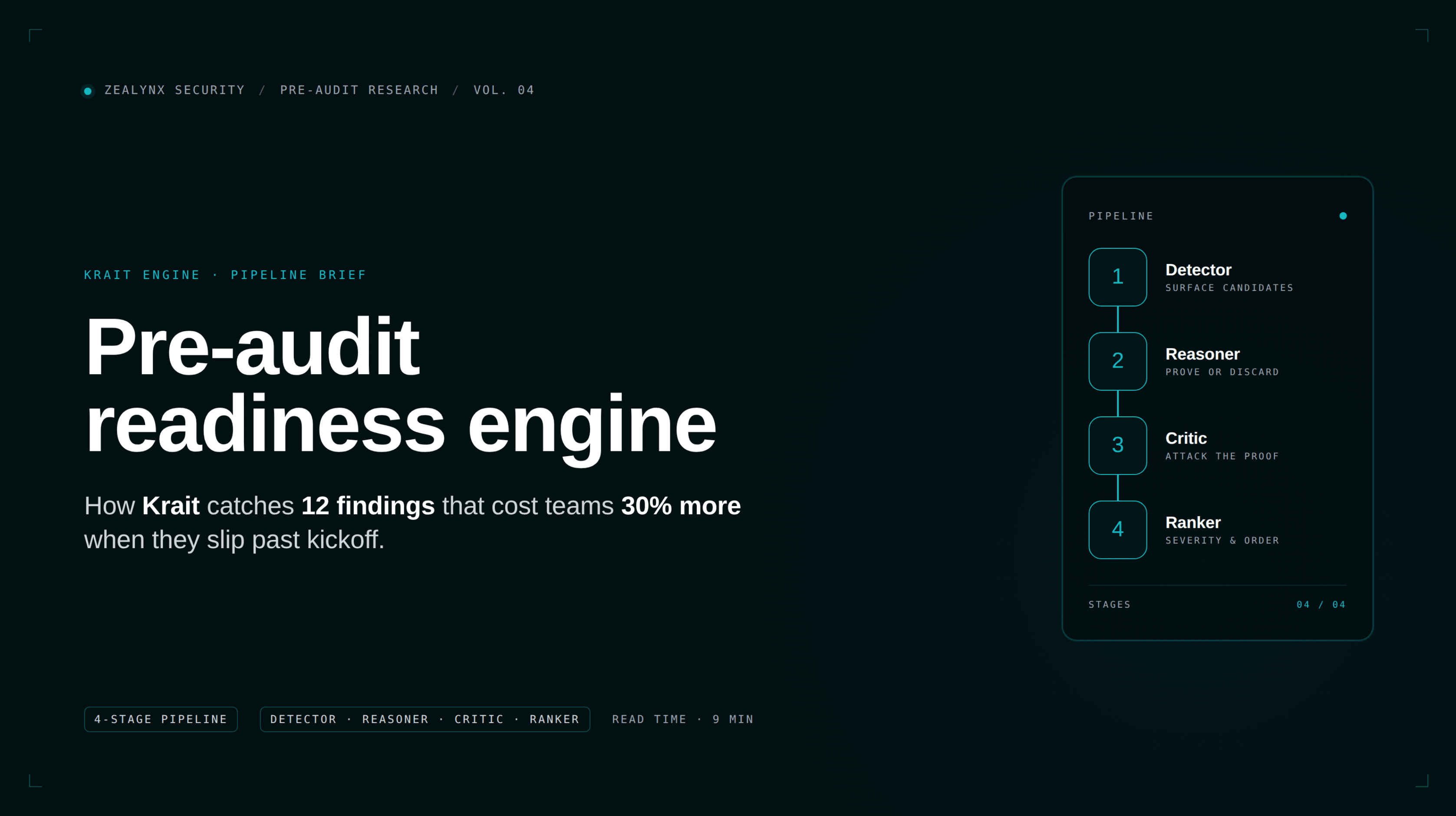

AI AuditsAuditToolsWeb3 Security
Pre-audit readiness engine: how Krait catches 12 findings that cost teams 30% more

16 min
If you have ever opened three audit quotes for the same protocol and watched the numbers spread by 80%, the cause is almost never the auditors. It is your repo.
Auditors charge for the time it takes to understand your code. When intent is undocumented, when invariants are not written down, when Slither runs hot with fifty warnings nobody triaged, when the test suite covers happy paths only, every one of those gaps converts directly into billable senior-researcher hours. Conservatively, you are paying a 30% tax on unpreparedness before a single line is reviewed.
Krait is the tool we built to make that tax go to zero. This article walks through what a pre-audit readiness engine actually has to do, how Krait's 4-phase pipeline works, and the twelve finding categories Krait surfaces before your auditor ever opens the repo.
Before you book the audit slot
Run Krait first. Bring a verified readiness score to your auditor.
Krait catches the obvious findings so your paid audit hours go to economic and logic bugs, not reverse-engineering intent. When your scope is locked, request a Zealynx quote and we will map the review around the work that actually requires human eyes.
In this article:
- The cost drivers that turn a fair audit quote into a 30% premium, and where Krait intervenes in the funnel.
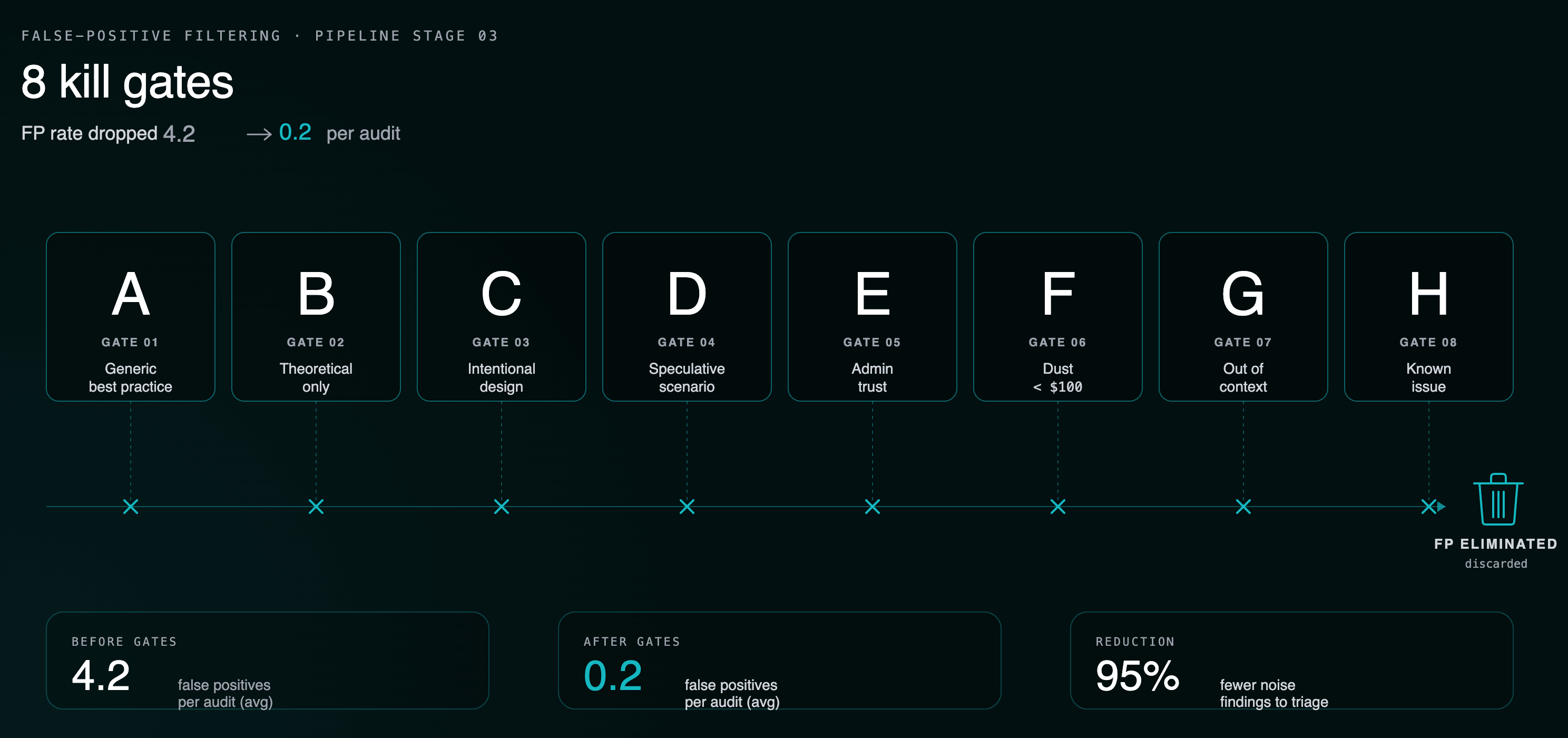
- How Krait's 4-phase pipeline (Detector → Reasoner → Critic → Ranker) drove false-positive rate from 4.2 per contest to 0.2.
- The 12 finding categories Krait surfaces, with concrete examples from the public shadow-audit benchmark.
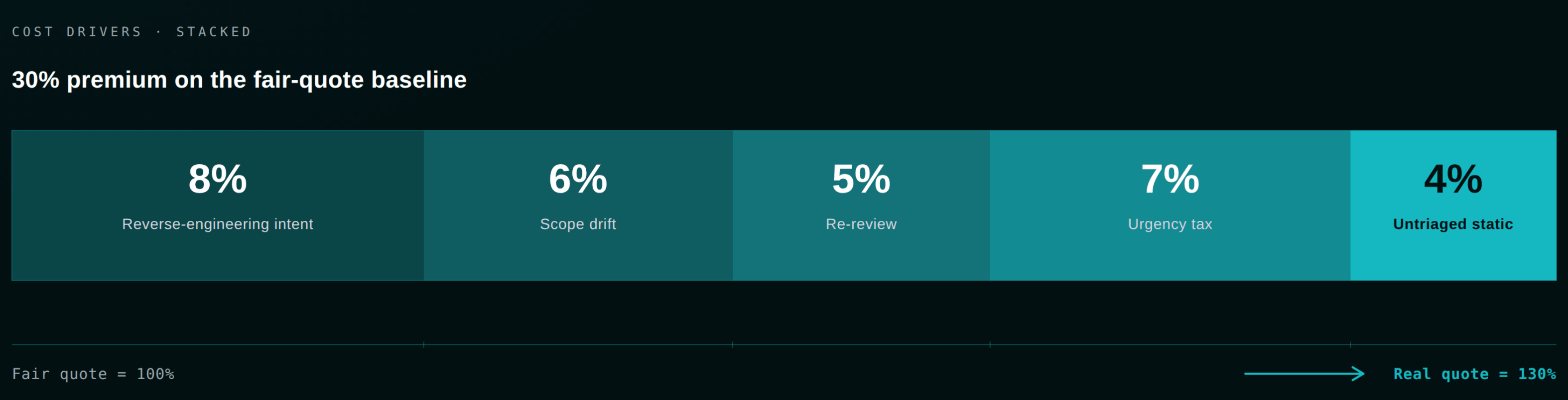
Why audit quotes are 30% larger than they should be
The cost drivers below come from our own 2026 audit pricing breakdown and recurring patterns across our engagements.
| Cost driver | Typical impact | Why it happens |
|---|---|---|
| Reverse-engineering intent | 1500 / day of auditor time | No NatSpec, no architecture diagram, no invariants list. |
| Scope drift mid-engagement | +10–30% on final bill | External integrations not declared up front, force re-scoping. |
| Re-review after fixes | +10–30% | Shifted line numbers, broken commits, "one change" during the freeze. |
| Urgency premium | +30–50% | You booked the slot too late. |
| Untriaged static analysis | Hours per noisy report | Slither and Aderyn warnings nobody handled. |
Stack two of those and you are at 30% over your fair-quote baseline. A well-prepared codebase, by contrast, reliably earns a 15–25% lower quote. In a 15–25K. In a $500K bridge audit, it is six figures. The same logic applies whether you are budgeting against our 2026 pricing guide or the ROI framework for justifying audit spend.
What a pre-audit readiness engine actually has to do
The market is full of "AI audit tools" that run a single LLM pass over your contracts and dump every possible issue. We tested those approaches building Krait. The early versions failed in exactly the way you would expect: an FP explosion. Our v3 methodology hit one contest with a 100% false-positive rate. We published the failure in the shadow-audits folder on GitHub rather than quietly tuning it away, then rebuilt the pipeline from scratch.
A real pre-audit readiness engine has to do three things at once.
Detect like an auditor. Not pattern-match against a fixed checklist. Reason about the code in context. A reentrancy guard is not enough if the external call is in the wrong place. An access-control modifier is not enough if it can be re-initialized by anyone.
Eliminate false positives. A 50-finding report with three real bugs and 47 false alarms is worse than no report. Your team learns to skim past the warnings, which is exactly when the real one gets missed.
Cover the process gaps that code analysis cannot see. Frozen commit hash.
scope.txt. NatSpec coverage. Invariant list. Branch coverage report. These do not show up in a static analyzer. They show up in your auditor's first kickoff call, and they are the single largest driver of the 30% tax. Most of these are spelled out check-by-check in the Zealynx pre-audit technical checklist.How Krait works: the 4-phase pipeline
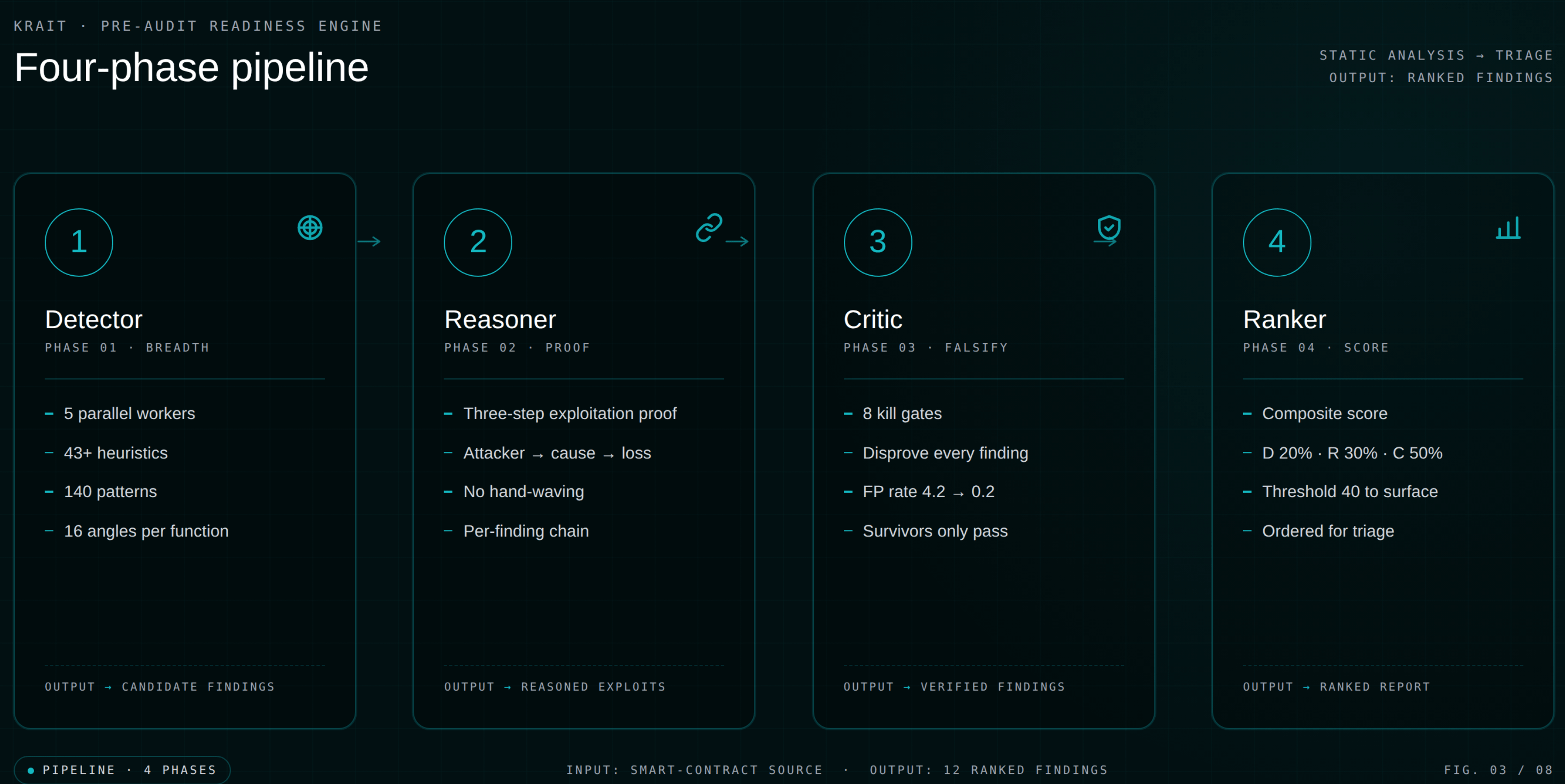
When you run
/krait on a Solidity project inside Claude Code, Cursor, Windsurf, or Codex, the methodology executes in four phases. Each phase narrows the funnel before the next one starts.Phase 1: Detector. Five parallel workers scan every file using 43+ detection heuristics, 140 vulnerability patterns, and a 9-category Feynman interrogation system (Purpose, Ordering, Consistency, Assumptions, Boundaries, Returns, External Calls, Protocol Integration, Overrides). From v7 onward, each function is examined from 16 angles: 4 technical lenses crossed with 4 independent mindsets.
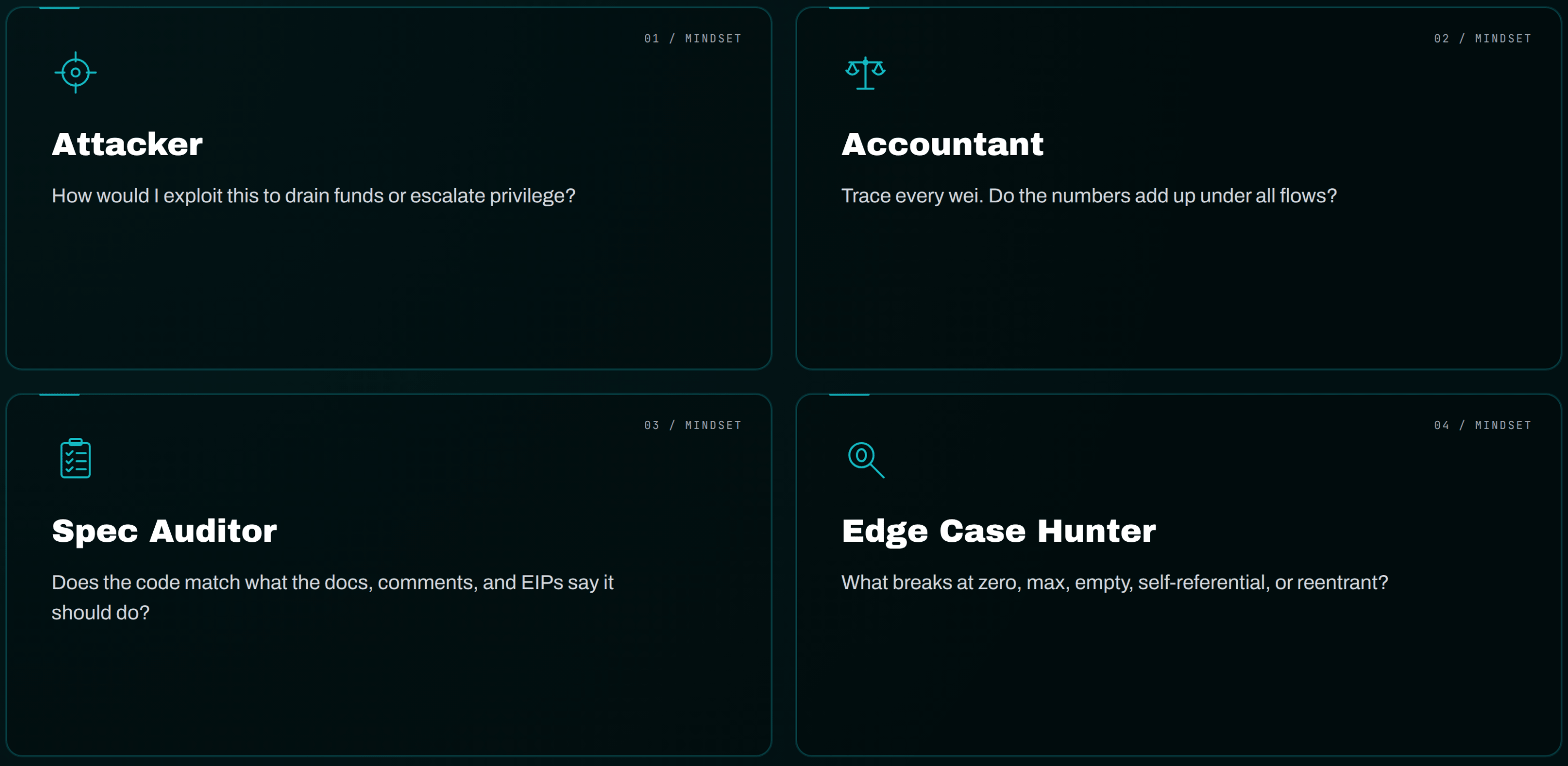
The four mindsets are the interesting part:
| Mindset | What it asks |
|---|---|
| Attacker | "How would I exploit this to drain funds or escalate privilege?" |
| Accountant | "Trace every wei. Do the numbers add up under all flows?" |
| Spec Auditor | "Does the code match what the docs, comments, and relevant EIPs say it should do?" |
| Edge Case Hunter | "What breaks at zero, max, empty, self-referential, or reentrant?" |
Findings that get flagged by multiple mindsets earn a consensus boost. Single-source findings get extra scrutiny in the next phase.
Phase 2: Reasoner. Every candidate finding must produce a three-step exploitation proof: attacker does X, causes Y, results in Z loss. No hand-waving allowed. If you cannot construct a concrete attack path, the finding does not survive.
Phase 3: Critic. This is the false-positive elimination layer, and the difference between Krait and a single-pass scanner. Eight Kill Gates actively try to disprove every finding: (A) generic best practice, (B) theoretical, (C) intentional design, (D) speculative with no WHO/WHAT/HOW MUCH, (E) admin trust, (F) dust under $100, (G) out of context (mocks, scripts), (H) known issue. The Critic dropped Krait's FP rate from 4.2 per contest to 0.2. It has never killed a true positive across 40 shadow audits.
Phase 4: Ranker. Composite scoring: Detector 20%, Reasoner 30%, Critic 50%. Threshold 40/100 to surface. Severity ranked, fix-suggested, exploit-trace included.
Output is a structured JSON in
.audit/krait-findings.json plus a markdown report. Every finding lands at an exact file:line with vulnerable code, suggested fix, and a written exploit trace. Upload the JSON to the web platform for a branded report your auditor can read in five minutes.The numbers, for reference: tested blind against 40 Code4rena, Sherlock, and CodeHawks contests. v6.4 hit 90% precision at 0.2 FPs per contest. v7 and v8 hit 100% precision across their most recent 5-contest cycles. Every shadow audit is reproducible from the public repo.
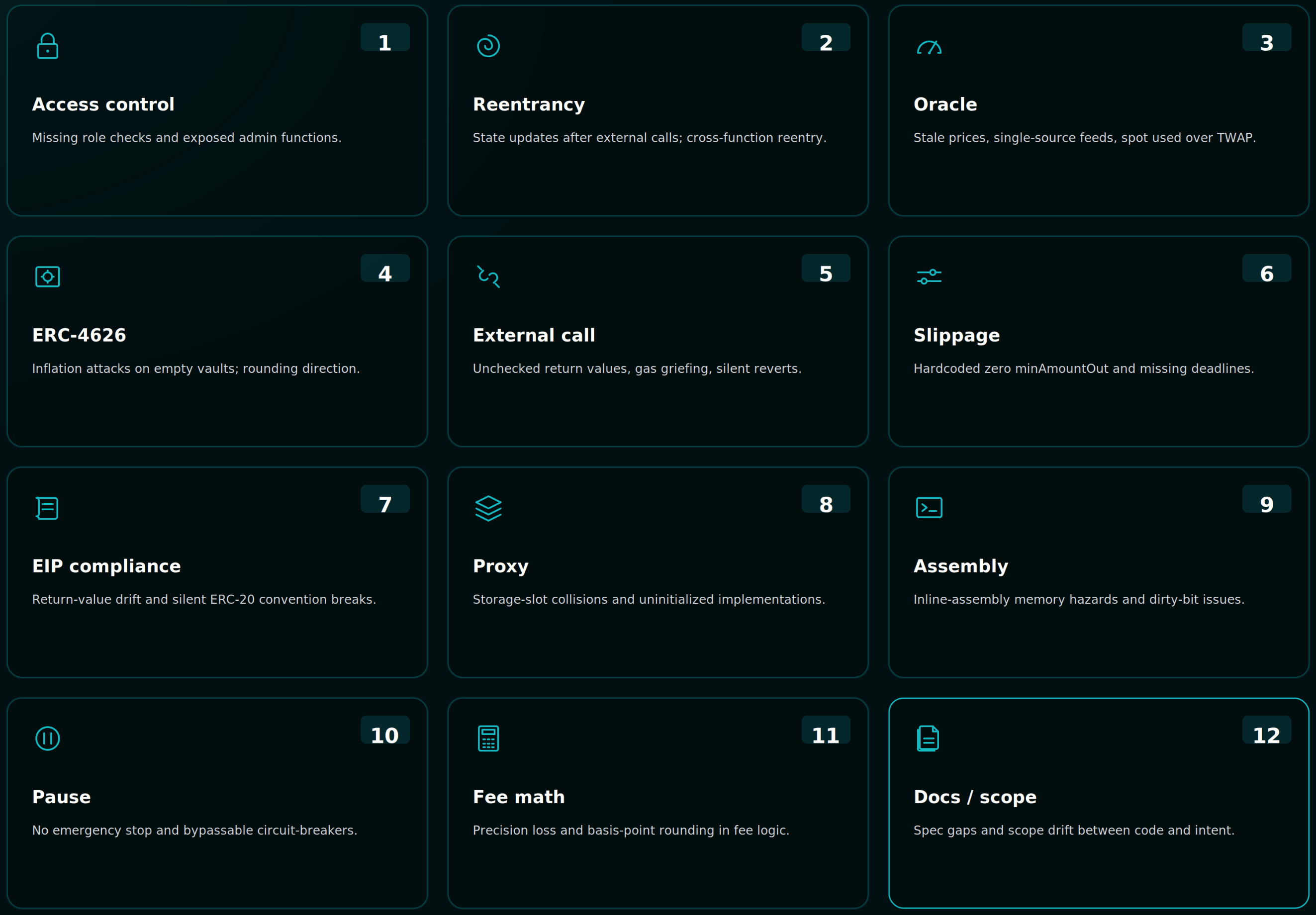
The 12 findings that show up before the auditor
These are the categories Krait surfaces in a typical first run on a DeFi protocol. Eleven are CLI-level outputs from the four-phase pipeline. The twelfth is the web platform's 845-check assessment, which covers the process gaps your
/krait run cannot see.If your auditor finds any of these on Day 1 of a paid engagement, you are paying $1500/day to do work the tool would have done for free.
1. Access control gaps
Improperly scoped modifiers, missing
onlyOwner on initialization, role-based controls that allow self-elevation, public functions that should be internal. Per OWASP's 2026 smart contract incident data, this is the single most frequent vulnerability class for the second consecutive year. Krait's detector primer covers admin model, role granting paths, and initializer protection.2. Reentrancy and CEI violations
Not just classic single-function reentrancy. Cross-function reentrancy, read-only reentrancy (the Curve / Lido pattern), and CEI ordering bugs where state updates happen after external calls. The Krait Detector flags coupled state pairs that per-function scanning misses.
3. Oracle freshness and manipulation
Stale price reads, missing heartbeat checks, single-source oracle dependencies, instantaneous spot reads in Uniswap V3 pools where the TWAP should be used. For lending and AMM protocols, Krait loads a 15-pattern domain primer with patterns derived from Aave V3 staleness findings and similar.
4. ERC-4626 and first-depositor inflation
The donation attack. First-depositor share-price inflation. Rounding direction errors in
convertToShares / convertToAssets. Krait's shadow-audits/ folder documents catching this exact class on the Basin contest. Vault standard compliance is one primer query and runs in seconds. The AMM security foundations guide covers the underlying invariant logic.5. Unchecked external call returns
Low-level
.call() results ignored. Token transfers without SafeERC20. Cross-contract calls where a false return triggers silent failure. The mechanical version is what Slither catches if you run it; the subtle version is what the Reasoner phase surfaces by tracing the consequence of a silent failure two hops downstream.6. Slippage and deadline omissions
Swap calls without
amountOutMin, no deadline parameter, hardcoded slippage tolerances, missing checks on block.timestamp for liquidity operations. Krait's DEX/AMM primer carries 20 attack patterns from sandwich and MEV findings on Code4rena.7. EIP and ERC compliance drift
The contract claims ERC-4626 but
redeem rounds the wrong direction. The contract uses EIP-712 but the domain separator is constructed with the wrong type hash. The contract emits ERC-20 events but does not actually transfer. Krait's Spec Auditor mindset is purpose-built for this and caught an EIP-712 mismatch on the reNFT shadow audit.8. Proxy and upgrade safety
Are you audit-ready?
Download the free Pre-Audit Readiness Checklist used by 30+ protocols preparing for their first audit.
No spam. Unsubscribe anytime.
Storage slot collisions across implementations. Missing initializers. UUPS implementations without
_authorizeUpgrade. Function selector clashes in Diamond patterns. The Proxy primer carries 94 checks across 15 patterns. We have written separately about why UUPS dominates and where it bricks; Krait runs the equivalent analysis on your bytecode. For deeper coverage, see the proxy upgradeability security checklist.9. Assembly and encoding bugs
Inline assembly using the wrong opcode.
mload where sload was intended. Custom encoders that pack the wrong number of bytes. Krait caught a DittoETH add vs and bug on the shadow audit, the kind of one-character difference that sails past line-by-line manual review. The Edge Case Hunter mindset is tuned for this.10. Pause and emergency-stop bypass
Functions tagged
whenNotPaused that have alternate code paths. Modifiers that fail open instead of fail closed. Emergency withdraw functions that bypass intended guards. Lifecycle bugs in pause / unpause logic that allow re-entry through a sibling function.11. Accounting and fee math errors
Fee calculations applied at the wrong step. Reward accumulators that double-count. Vault claim logic where fees are not deducted before the share calculation. Krait caught a real one on the LoopFi shadow audit: the AuraVault claim double-spend, where fees were not deducted and the vault drained over time. The Accountant mindset traces every wei through every state transition.
12. Documentation, invariant, and scope gaps
This is the category your CLI run will not catch and your web assessment will. Frozen commit not tagged.
scope.txt missing or outdated. NatSpec coverage under 60% on public interfaces. No documented invariants, which means the auditor cannot run Halmos or Certora. Test coverage report shows line coverage instead of branch coverage.This category is the single largest cost driver. If you have read our pre-audit checklist post, this is the checklist re-rendered as automated checks against your repo.
What the readiness report looks like
When
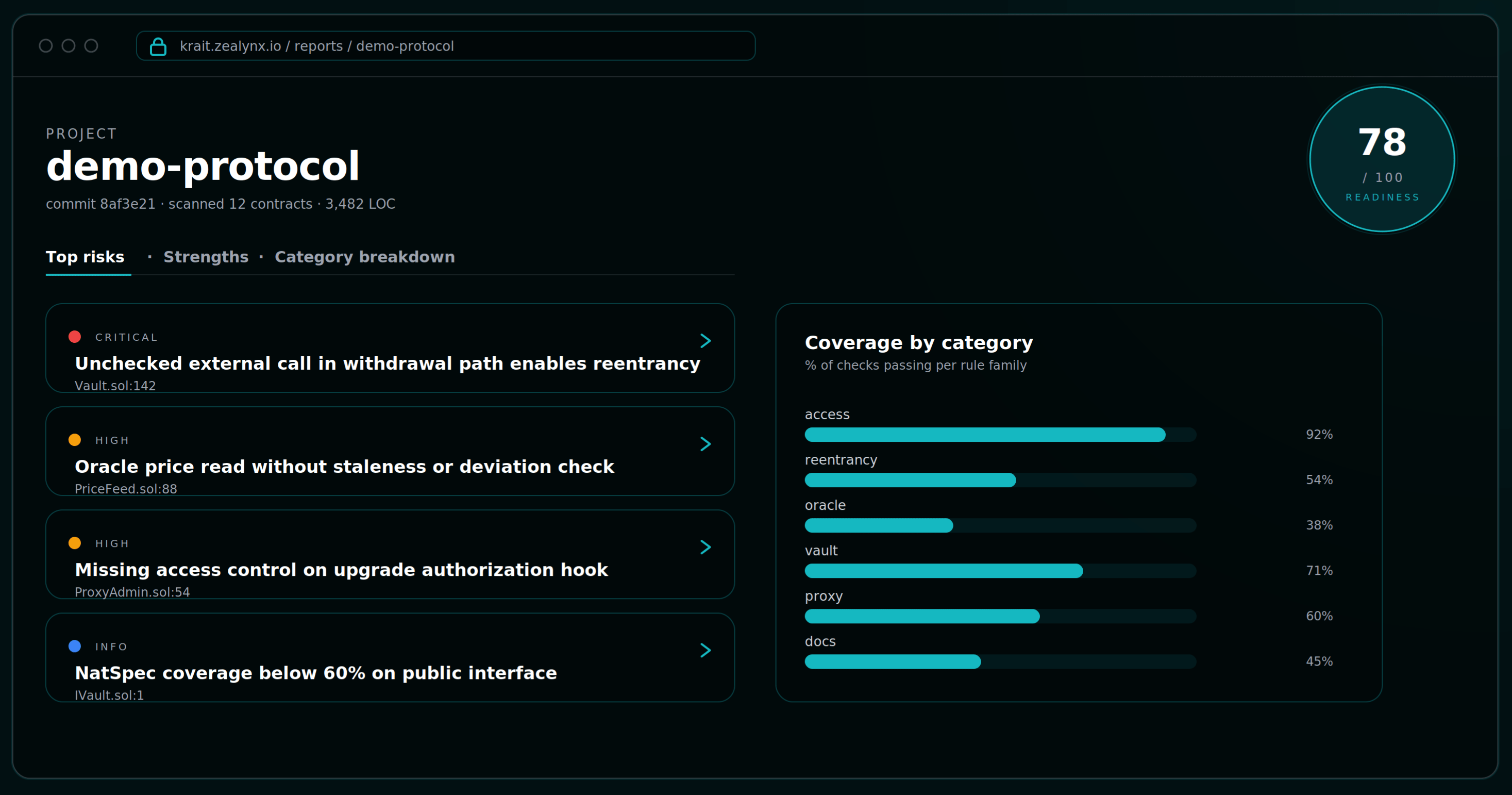
/krait finishes and you upload the JSON, or when you complete the web assessment directly, the report is structured for the conversation with your auditor. Everything you need to share is on one screen.- Readiness Score out of 100. Pass / fail / skip breakdown. We recommend 70+ before you talk to a firm.
- Top Risks: ranked critical and high findings, each linked to a Solodit precedent.
- Architectural Security Observations: the "senior auditor executive summary" lines.
- Security Strengths Observed: what you are doing right. Investors and partners read this section. The same artifacts double as evidence inside an audit-investors due-diligence pack.
- Category Breakdown: every check organized by section, pass / fail / skip, expandable details with file:line references.
- Evidence Appendix: tool outputs, code references, manual notes per check.
Export as Markdown, share a URL, or upload the JSON directly to your auditor. The combined readiness score, if you run both surfaces, weights the web assessment at 60% (process maturity) and the CLI scan at 40% (code-level findings). That ratio reflects what actually predicts engagement length and cost.
How this fits into the audit funnel
Three steps. Eight to ten days if you start clean.
Day 0: Run Krait. Clone
github.com/ZealynxSecurity/krait, copy the skills into ~/.claude, run /krait in your project. Output lands in .audit/krait-findings.json and a markdown summary. Upload to the web platform for the branded view. Run the web assessment in parallel.Days 1–5: Fix what Krait found, then prepare like a pro. Triage the report. Fix the high and critical findings. For the medium and low, document the ones you decline to fix and why. Then work through the Zealynx pre-audit checklist: freeze the commit, write the invariants list, get NatSpec to 100% on public interfaces, hit branch coverage on the core.
Day 7+: Request a scoped audit quote. Bring the Krait report. The auditor reads it, scopes their review around what is left, and quotes the engagement at the well-prepared price band. The 30% tax goes to zero. For the full timeline from kickoff to delivery, see how a Zealynx audit timeline actually works. After delivery, the post-audit security playbook covers monitoring, hotfix cadence, and second-engagement triggers.
Get in touch
Krait is free. The web assessment runs in your browser. The CLI runs locally inside Claude Code on your existing subscription. No API keys, no install friction, no calls scheduled.
If you have already run Krait and want a human security review on top, request a Zealynx audit quote and attach the Krait JSON. We will scope the engagement around what Krait could not reach, which is usually where the highest-leverage bugs live anyway. You can also browse our smart contract audit service page for engagement formats, sample reports, and previous work.
- Run Krait (free): krait.zealynx.io
- Request a Zealynx quote: zealynx.io/quote
- Browse audit services: zealynx.io/services/smart-contract-audits
FAQ
1. What is a pre-audit readiness engine, and how is it different from Slither or a single-pass AI scanner?
A pre-audit readiness engine is a tool that simulates a senior security researcher's first pass on your repo before you pay one. The difference from Slither or Aderyn is that those are pattern-matchers — they emit warnings whether or not the pattern is actually exploitable in your code. The difference from a single-pass LLM scanner is the false-positive layer. Krait's Critic phase runs eight Kill Gates against every candidate finding and discards anything that fails a reasoned attack-path test. That dropped FP rate from 4.2 per contest to 0.2 across 40 public shadow audits. The result is a report your auditor can read in five minutes instead of a hundred-line dump that buries the real bugs. See the methodology under pre-audit preparation.
2. Is Krait a replacement for a manual smart contract audit?
No. Krait is a pre-audit readiness engine. It catches the categories of finding that should never reach a paid auditor: mechanical bugs, spec-compliance drift, undocumented assumptions, missing invariants. Manual audits exist to find economic exploits, business-logic flaws, and design-level vulnerabilities that require human reasoning about the protocol's purpose. Krait makes those human hours go further by clearing the noise first. The product page at
krait.zealynx.io is explicit about this: "AI-powered security assessment. Not a replacement for professional audit." The Zealynx audit ROI guide explains where the human review still pays for itself.3. What does the 0–100 readiness score actually predict, and what number should I aim for?
The score is a composite: 60% from the 845-check web assessment (process maturity — docs, invariants, scope, freeze discipline, monitoring) and 40% from the CLI scan (the 12 vulnerability categories). It is calibrated against what predicts engagement length and cost. A score of 70+ correlates with the lower price band in our 2026 audit pricing breakdown. Below 50 and you should expect the urgency tax — auditors will need to do the prep work you skipped, on the clock. Aim for 70 minimum before you talk to a firm; aim for 85+ if you want to attract Tier-1 audit slots without a months-long wait.
4. Does Krait work with Cursor, Windsurf, or Codex, or only Claude Code?
It works with any IDE that runs an LLM agent. The CLI skills are written for Claude Code's skill system, but the web assessment's "Verify with AI" button generates copy-paste prompts that drop directly into Claude Code, Cursor, Windsurf, or Codex. You paste the agent's response back, Krait auto-parses the verdict, extracts the
file:line, and sets the status. There is no vendor lock-in to a single coding assistant.5. My protocol is in Rust on Solana, or Cairo on StarkNet. Does Krait cover non-EVM?
Today, the strongest coverage is Solidity. The pattern library has growing Rust / Solana coverage, but the shadow-audit benchmarks are EVM. If you are launching on Solana, we publish a separate 45-check Solana security guide and our Solana audit team can scope a manual review directly. The same applies to Cairo on StarkNet, Move on Aptos/Sui, and Rust on Soroban — those reviews happen through the Zealynx smart contract audit service.
6. Will my code leave my machine when I run Krait?
The CLI runs locally inside your Claude Code session. The same data-handling rules that govern your existing Claude subscription apply — Krait does not add a new outbound channel. If you upload findings JSON to
krait.zealynx.io/report/findings for a branded report, that specific JSON goes to the web platform; if you want to keep everything local, the CLI markdown output is enough to share with your auditor. The web assessment itself is browser-based and persists state in localStorage by default. You can read the architecture details in the Zealynx Krait announcement post.Glossary
| Term | Definition |
|---|---|
| Audit Readiness | The state of a protocol's codebase and documentation being prepared for a formal security audit. |
| Shadow Audit | A time-boxed exercise auditing a known-graded protocol fork, with findings scored against the published contest results. |
| Pre-Audit Readiness Engine | A pipeline that simulates a senior security researcher's first pass on a repo to catch findings before the paid audit begins. |
Are you audit-ready?
Download the free Pre-Audit Readiness Checklist used by 30+ protocols preparing for their first audit.
No spam. Unsubscribe anytime.